You want to use Python’s unittest.mock library to test your code? Great idea. Let me explain the basics with examples and visuals.
What is mocking?
Mocking (or patching) is the process of replacing parts of your code (“stubbing”) during unit testing in order to:
a) Focus your tests; making sure each tests checks one specific thing
b) Test that your callables (functions/classes) are called the way you expected
The most common library in Python land is the builtin library unittest.mock. There are alternatives like flexmock but I will not be focussing on those.
What is a Mock?
We will be stubbing parts of our code and replace those parts with Mock objects. What exactly is this object?
Mock is a very flexible object. You can call it in all kinds of ways, assign attributes, look up attributes, and it will not complain.
Let me give you a few examples:
In [1]: from unittest.mock import Mock In [2]: m = Mock() In [3]: m() Out[3]: <Mock name='mock()' id='4492582136'> In [4]: m()()() Out[4]: <Mock name='mock()()()' id='4492723144'> In [5]: m.foo() Out[5]: <Mock name='mock.foo()' id='4492606320'> In [6]: m.bar().baz.xyz() Out[6]: <Mock name='mock.bar().baz.xyz()' id='4493125280'> In [7]: m.foo Out[7]: <Mock name='mock.foo' id='4492606768'> In [8]: m.foo = 'bar' In [9]: m.foo Out[9]: 'bar'
It’s capable of a lot more, but we’ll get to that in a bit.
Mocking basics
Let’s see how mocking works in practice.
Here is a part of our code base:
# app/utils/my_module.py
def greet(name):
print(f'Hello, {name}')
def greet_group(group):
for name in group:
greet(name)
Let’s show how patching works and what it looks like.
# app/utils/tests/test_my_module.py
from unittest.mock import patch
from app.utils.my_module import *
def test_greet_group_without_patch():
greet_group(['Bob', 'Alice'])
def test_greet_group_with_patch():
with patch('app.utils.my_module.greet') as mock_greet:
greet_group(['Bob', 'Alice'])
The test output will look like this (I’m using pytest):
app/utils/tests/test_my_module.py::test_greet_group_without_patch Hello, Bob Hello, Alice PASSED app/utils/tests/test_my_module.py::test_greet_group_with_patch PASSED
Notice that
- First test, without patching, shows that
greetis being executed, twice. - Second test, with patching, shows that it isn’t.
I promised that this was going to be a visualized explanation, so let me try to clarify using a drawing:
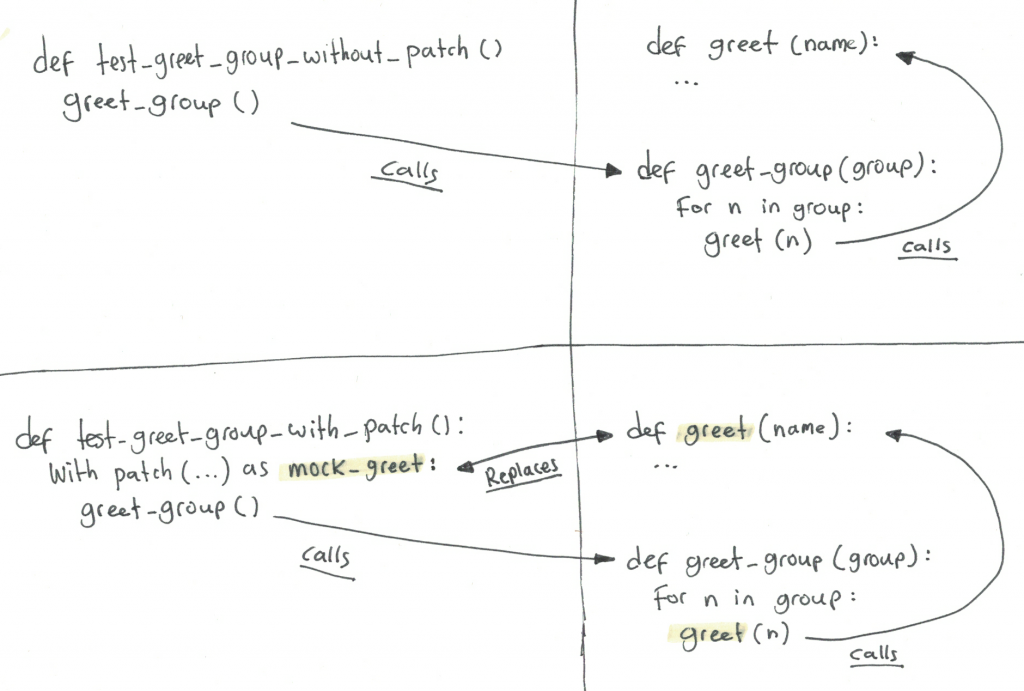
I hope that clarifies it a bit. Now, obviously these tests are not doing anything useful. Let’s add an assertion. If we were to examine the mock instance after running test_greet_group_with_patch, we would be able to see the calls to the instance:
(Pdb) mock_greet
<MagicMock name='greet' id='4461253688'>
(Pdb) mock_greet.call_args_list
[call('Bob'), call('Alice')]
This proves that mock_greet received two calls, one with argument Bob, one with Alice.
Mock objects have built-in assertion methods. For this test case, we will be using assert_any_call, which will check if the Mock object was called with the given argument.
def test_greet_group_with_patch():
with patch('app.utils.my_module.greet') as mock_greet:
greet_group(['Bob', 'Alice'])
mock_greet.assert_any_call('Bob')
mock_greet.assert_any_call('Alice')
Mock offers several call assertion methods, including assert_called_once_with, which is the one I use most frequently.
Return values and side effects
When using mocks, you are usually replacing (stubbing) callables. Let’s go over the basics:
- A callable is an object which can be called. This will usually be a class, function or method.
- A return value is the thing that calling that object returns.
- In Python (and other object oriented languages), a callable can return another callable.
- A side effect is something the callable does that has effect on the world, but it is not the return value.
A Mock’s return_value attribute is equal to the result of calling it. Arguments are ignored:
In [2]: m = Mock()
In [3]: m() is m.return_value
Out[3]: True
In [4]: m('test') is m.return_value
Out[4]: True
In [5]: m()() is m.return_value.return_value
Out[5]: True
Time for examples. The following example code contains a class, a method and a function that instantiates the class and calls its methods:
class FooClient():
def login(self):
pass
def foo(self, arg):
pass
def do_foo():
foo_client = FooClient()
foo_client.login()
foo_client.foo('bar')
This test patches the complete client and is going to test the do_foo function:
def test_do_foo():
with patch('app.utils.my_module.FooClient') as mock_foo_client:
do_foo()
breakpoint()
But for now, let’s jump in the debugger to show how to use the return_value attribute.
# Yes, this is the mock of FooClient:
(Pdb) mock_foo_client
<MagicMock name='FooClient' id='4545390016'>
# It has been called, once, with no arguments.
# This shows the instantiation of the class.
(Pdb) mock_foo_client.call_args_list
[call()]
# Its return value, the class instance, has a callable "login"
# which has been called, once, with no arguments:
(Pdb) mock_foo_client.return_value.login.call_args_list
[call()]
# Its return value's callable "foo" has been called too,
# once, with argument "bar":
(Pdb) mock_foo_client.return_value.foo.call_args_list
[call('bar')]
Extending the test to assert these calls could look like this:
def test_do_foo():
with patch('app.utils.my_module.FooClient') as mock_foo:
do_foo()
mock_foo.assert_called_once_with()
mock_foo.return_value.login.assert_called_once_with()
mock_foo.return_value.foo.assert_called_once_with('bar')
Let’s try to visualize this:
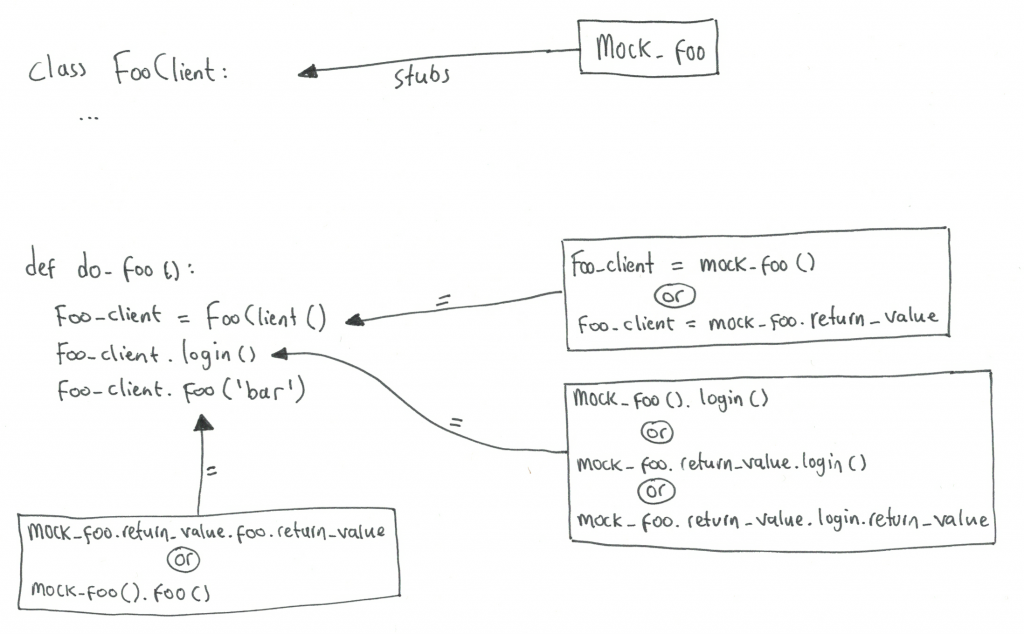
[ work in progress ]