Recently I was asked to develop a config parser, or more specific, a config converter, in Python. The purpose of this tool was to parse a particular config file and feed it into an API. This relatively simple task was complicated by a few parameters:
- The input file sizes are in the range 10-15G
- The input is a undocumented proprietary format
- The output needs to be inserted in a certain order because of dependencies
- This process needs to be as fast as possible
This is a broad overview of how I attempted to solve some of these issues.
Performance watching
First of all, speed was the main requirement. I used a few tools to keep an eye on performance while developing.
- Profiling code using
cProfileandgprof2dot. This combination of tools generates nice, readable performance graphs like this one (deliberately obfuscated):
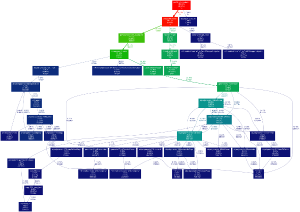
Quickstart to profiling:
python -m cProfile -o profile.out myscript.py gprof2dot -f pstats profile.out | dot -Tpng -o profile.png
- Good old Unix tool
timeand Python’stimeit. Great ways to compare speed of different implementations and to keep an eye on any regressions. Pro tip:Jupyter Notebookcontains a%timeitmagic operator to time cell execution.
Optimizing file reading
There are few methods to speed up file input in Python:
- Depending on the characteristics of your machine (disk speed, memory speed, CPU speed) it can be faster to read chunks than to read per-line.
- When reading chunks, pick a good chunk size. The ideal size basically depends on the specifics of the machine the script is running on. In this case, the optimal size for the target machine was around 20MB.
- If the file needs to be parsed per-line, use
str.splitlines()on each chunk. - When not reading chunks, use iterating per-line (
for line in file_obj). Don’t usefile_obj.readlines(), at least not on large files, as it loads the complete file into memory. - Set the correct encoding right away and read in text mode. Decoding on-the-fly is faster than decoding chunks (or lines). The time you might save by reading in bytes mode is negated by the time it takes to decode the data.

Insert order / dependencies
Basically, the input format is (might be) in a different order than the desired output format. There are several “types” of config blocks, and a config block of type X at the end of a 15G file could be the first items that needs to be processed. This order is predetermined (“Y blocks go before Z blocks”). However,
- We don’t know what’s in the file before reading the full file
- The file does not fit into memory, especially not after converting to Python objects
- Remember, it needs to be fast!
From points (1) and (2), it’s clear that, first, we need to read the complete file, without storing it in memory. This is done by reading the file and storing the beginning and end byte positions of each config block. However, this is also a lot of data, so it’s not stored in memory but in “intermediate” files instead – one file per config type.
Then, to get all config blocks of a certain type, we can read the intermediate file for that type and use the pointers to seek and read data from the config file.
Cons: Read and write operations on the file system can be slow, especially when using spinning disks. Some free disk space is required.
Pros: Very low memory footprint. Relatively fast.
Parsing
The fun part. These config files are in a proprietary format that looks like a common data format, but unfortunately it isn’t. We are talking about a structured key-value format with some custom/proprietary data types.
I started out using regular expressions, but quickly came to the conclusion that the data included nesting. This immediately disqualified regular expressions, and I used a parsing library instead. I tried three different libraries:
- Parsley. I started out using this library. The scarce documentation and awkward syntax moved me to PyParsing, as I could not get it to do what I wanted.
- PyParsing. A mature library with extensive docs and readable code. This is the library I ended up using.
- SimpleParse. I gave this library a shot because it promises to be a fast parser (and speed is important). In my case, it unfortunately ended up being slower than PyParsing. Anyway, a nice excuse to write some beautiful EBNF grammar.
The downside of using a parsing library is that it introduces performance overhead. Eventually, I opted for a solution that uses a combination of PyParsing and stdlib code for optimal performance.
Multiprocessing
It’s 2017, so single core machines don’t exist anymore. This tool needs to be as fast as possible, so it would be silly not to utilize parallelization.
Python offers several ways to implement parallelization, of which the multiprocessing module is by far my favorite. It is a flexible module that provides high-level building blocks to write a multi-core application. A rough overview of how I used it:
- A worker function that listens on a queue
- A producer function that generates queue messages
- A Queue
- Tune the number of producers and workers (total amount may even exceed the number of cores)
- Write logic that cleans up and handles exceptions gracefully
Result
My solution consists of two stages: The first stage generates intermediate files. On a machine with a reasonably fast SSD, this takes about 50 seconds per GB.
The second stage reads those intermediate files, converts config blocks to Python data types, and feeds them into an API. This process is CPU-bound, so processing time can be decreased by using a faster host.
On my test VM with two cores and four workers, this process takes about 10 minutes per GB. The majority of this time is spent in the PyParsing library. This process is parallelized, and can thus be optimized by using fast hardware and tuning the number of workers.